Asumsi untuk pengujian hipotesis yang
didasarkan pada model ANOVA faktor tunggal sebenarnya berhubungan dengan
nilai residual atau error (εij). Banyak referensi yang
menyatakan bahwa ANOVA faktor tunggal cukup handal terhadap asumsi ini,
misalnya Uji F tetap handal dan dapat diandalkan meskipun asumsi tidak
terpenuhi. Meskipun demikian, tingkat kehandalannya sangat sulit diukur
dan tergantung juga pada ukuran sampel yang harus seimbang. Uji F bisa
menjadi sangat tidak dapat diandalkan apabila ukuran sampel tidak
seimbang, apalagi jika ditambah dengan sebaran data yang tidak normal
dan ragam tidak homogen. Oleh karena itu, saya sangat merekomendasikan
untuk memeriksa terlebih dahulu asumsi ANOVA sebelum melanjutkan ke
tahap analisis.
Bagaimana apabila kita menganalisis data
yang sebenarnya tidak memenuhi asumsi analisis ragam? Apabila hal itu
terjadi, maka kesimpulan yang diambil tidak akan menggambarkan keadaan
yang sebenarnya bahkan menyesatkan! Dengan demikian, sebelum melakukan
analisis ragam, terlebih dahulu kita harus memeriksa apakah data
tersebut sudah memenuhi asumsi dasar analisis ragam atau belum.
Strategi umum untuk memeriksa asumsi
ANOVA serta urutan asumsi yang harus diperiksa terlebih dahulu di bahas
secara detail oleh Dean dan Voss (1999). Mereka menitikberatkan pada
pengamatan plot residual, dengan alasan berikut: pemeriksaan plot
residual lebih subjektif dibanding dengan pengujian formal dan yang
lebih penting, plot residual lebih informatif tentang sifat dari
masalah, konsekuensi, dan tindakan korektif yang bisa diambil.
Coba anda perhatikan model linier untuk rancangan RAL (One Way Anova) atau RAK berikut ini:
Model linier untuk RAL (One Way Anova):
Yij = μ + τi + εij.
dan model linier untuk RAK:
Yij = μ+ τi + βj + εij,
dimana εij ≈ NIID(0, σ2)
NIID = Normal, Independent, Identically Distributed dengan rata-rata 0 dan ragam σ2
Dalam prakteknya, makna yang tersirat dari model tersebut adalah:
- Data pengamatan dari setiap kelompok perlakuan berasal dari populasi normal/berdistribusi normal (ini diperlukan sehingga εij terdistribusi secara normal).
- Semua kelompok perlakuan mempunyai ragam yang homogen (ini diperlukan sehingga εij akan memiliki ragam homogen untuk setiap taraf perlakuan, i).
- Unit satuan percobaan ditentukan dan ditempatkan secara acak pada setiap kelompok perlakuan (ini diperlukan sehingga εij independen (saling bebas) satu sama lain).
- Pengaruh dari faktor perlakuan (τi) dan lingkungan (βj) dan galat (εij) bersifat aditif, maksudnya tinggi rendahnya respons semata-mata akibat dari pengaruh penambahan perlakuan dan atau kelompok. Nilai Respons (Yij) merupakan nilai rata-rata umum (μ) ditambah dengan penambahan dari perlakuan (τi) dan galat (εij).
Dengan demikian, asumsi-asumsi yang harus dipenuhi dalam melakukan analisis ragam adalah, Normalitas, homoskedastisitas (kehomogenan ragam), Independensi (kebebasan galat), dan Aditif.
1. Normalitas
Normalitas berarti nilai residual (εij) dalam setiap perlakuan (grup) yang terkait dengan nilai pengamatan Yi harus terdistribusi secara normal. Jika nilai residual terdistribusi secara normal, maka nilai Yi
pun akan berdistribusi normal. Apabila ukuran sampel dan varians sama,
maka uji ANOVA sangat tangguh terhadap asumsi ini. Dampak dari
ketidaknormalan tidak terlalu serius, namun apabila ketidaknormalan
tersebut disertai dengan ragam yang heterogen, masalahnya bisa menjadi
serius!
1.1. Penyebab Ketidaknormalan
Dalam praktiknya, jarang sekali ditemukan
sebaran nilai pengamatan yang mempunyai bentuk ideal, seperti
distribusi normal, bahkan sebaliknya, kita sering menemukan bentuk yang
cenderung tidak normal (skewed atau multimodal) karena keragaman dari
sampling. Keragaman ini terjadi apabila ukuran sampel yang terlalu
sedikit, misalnya kurang dari 8–12 (Keppel & Wickens, 2004;
Tabachnick & Fidell, 2007), atau apabila terdapat outliers. Outlier
biasanya terjadi karena adanya kesalahan, terutama kesalahan dalam
entri data, salah dalam pemberian kode, kesalahan partisipan dalam
mengikuti instruksi, dan lain sebagainya.
Beberapa contoh kasus yang sebaran datanya cenderung tidak normal misalnya:
- Banyaknya parasit dalam kehidupan liar
- Perhitungan jumlah bakteri
- Data dalam bentuk proporsi atau persentase
- Skala Arbitrary, seperti pengujian 10 skala uji rasa
- Penimbangan objek yang sangat kecil, berhubungan dengan keterbatasan alat penimbangan.
Hal lain yang bisa merusak asumsi kenormalan ini adalah apabila dalam melakukan pengacakan (randomization) tidak sesuai dengan prinsip pengacakan suatu rancangan percobaan. Hal ini memungkinkan data akan menyebar secara tidak normal.
1.2. Konsekuensi
Konsekuensi akibat data yang tidak menyebar normal adalah akan menyebabkan keputusan yang di bawah dugaan (under estimate) atau diatas dugan (over estimate) terhadap taraf nyata percobaan yang sudah ditentukan (Kesalahan Jenis I).
Meskipun demikian, harus diingat bahwa
dalam asumsi analisis ragam (syarat kecukupan model), uji kenormalan
merupakan hal yang tidak terlalu penting dibandingkan dengan uji
lainnya, asalkan:
- Ukuran contoh yang besar dan jumlah sampel yang seimbang.
- Sepanjang seluruh sampel data mempunyai distribusi yang hampir sama
dan jumlah sampel sama atau hampir sama dan tidak ada penyimpangan yang
ekstrim, tidak diperlukan pengujian kenormalan.
1.3. Hubungan dengan kehomogenan ragam
Sebenarnya ada hubungan simultan antara
data yang menyebar secara normal dan data yang mempunyai ragam homogen.
Data yang ragamnya homogen akan menyebar secara normal, tetapi data yang
menyebar secara normal tidak selalu mempunyai ragam yang homogen.
1.4. Pengujian Kenormalan:
Kita dapat memeriksa asumsi normalitas dengan berbagai cara.
-
Uji kenormalan harus dilaksanakan pada masing-masing kombinasi perlakuan (cell by cell basis)
-
Periksa outliers, kemiringan (skewness) dan bimodality.
-
Histogram dan Stem-and-Leaf-Plot dari nilai observasi atau residual
-
Box plot
-
Koefisien kemiringan (skewness) and kurtosis
-
Plot grup Rata-rata perlakuan vs. residual
-
Plot grup Rata-rata vs Varians seharusnya tidak menunjukkan adanya korelasi
-
Normal Probabilitas plot antara nilai residual dengan nilai prediksi atau observasi, juga cukup informatif.
-
Formal Test: Shapiro-Wilk test; Kulmogorov-Smirnov test
-
Ada juga beberapa tes formal normalitas
(misalnya uji Shapiro-Wilks tes; goodness-of-fit seperti uji
Kulmogorov-Smirnov), namun menurut beberapa literatur, metode grafis
jauh lebih informatif dalam memeriksa asumsi ANOVA sebelum analisis
ragam dilakukan.
1.5. Solusi
-
Usahakan banyaknya ulangan sama untuk setiap perlakuan karena ukuran sampel yang seragam sangat handal terhadap ketidaknormalan.
-
Periksa outlier, hilangkan apabila point data tersebut tidak refresentatif atau cek kembali kebenaran data tersebut
-
Pendekatan selanjutnya untuk mengurangi
pelanggaran normalitas adalah memangkas nilai-nilai data pengamatan
yang paling ekstrim, dengan tujuan untuk mengurangi pengaruh dari
skewness dan kurtosis, misalnya, membuang 5 persen bagian atas dan bawah
dari suatu distribusi (Anderson, 2001).
-
Transformasi data
-
Uji non parametrik
» Pengujian ketidaknormalan data pengamatan akan dibahas pada topik tersendiri
2. Kehomogenan Ragam (homoskedastisitas)
Asumsi lain yang mendasari analisis ragam
adalah kehomogenan ragam atau asumsi homoskedastisitas
(homoscedasticity). Homoskedastisitas berarti bahwa ragam dari nilai
residual bersifat konstan. Asumsi homogenitas mensyaratkan bahwa
distribusi residu untuk masing-masing perlakuan/kelompok harus memiliki
ragam yang sama. Dalam prakteknya, ini berarti bahwa nilai Yij pada setiap level variabel independen masing-masing beragam di sekitar nilai rata-ratanya.
-
Ragam nilai residual dan ragam data pengamatan dalam grup yang sama seharusnya homogen
-
Dampak ketidakhomogenan ragam lebih
serius dibandingkan dengan ketidaknormalan data karena dapat
mempengaruhi Uji-F. Hal ini akan meningkatkan kesalahan tipe I (tampak
seperti ada pengaruh dari perlakuan padahal sebenarnya tidak ada)
-
Box plot data pengamatan seharusnya tersebar merata diantara kelompok perlakuan (among grup)
-
Sebaran residual harusnya merata pada saat diplotkan dengan nilai rata-ratanya
Ragam yang heterogen merupakan
penyimpangan asumsi dasar pada analisis ragam. Data yang seperti ini
tidak layak untuk dianalisis ragam. Artinya untuk bisa dianalisis ragam,
data harus mempunyai ragam yang homogen.
2.1. Penyebab Heteroskedastisitas
Pertama, penentuan taraf atau klasifikasi
dari faktor (variabel independent), misalnya jenis kelamin, varietas,
mempunyai keragaman alami yang unik dan berbeda. Kedua, manipulasi
faktor perlakuan yang menyebabkan suatu objek (tanaman, peserta, dsb)
mempunyai karakteristik atau perilaku yang cenderung lebih sama atau
berbeda dibandingkan dengan kontrol. Ketiga, keragaman dari respons
(variabel dependent) berhubungan dengan ukuran sampel yang kita ambil.
Keragaman bisa menjadi serius apabila ukuran sampel tidak seimbang
(Keppel & Wickens, 2004).
2.3. Konsekuensi Heteroskedastisitas
Ragam yang tidak homogen ditambah dengan
ukuran sampel yang tidak sama, dapat menjadi masalah serius pada
pengujian hipotesis dengan ANOVA. Pelanggaran terhadap asumsi ini lebih
serius dibandingkan dengan asumsi Normalitas, karena akan berdampak
serius terhadap kepekaan hasil pengujian analisis ragam. Wilcox et al.
(1986) dengan menggunakan data simulasi membuktikan bahwa:
- dengan empat perlakuan/kelompok dan ukuran contoh (n) sama, yaitu
sebelas, rasio standar deviasi terbesar dengan terkecil = 4:1 (berarti
rasio ragam = 16:1) menghasilkan tingkat kesalahan Tipe I untuk taraf
nyata 0.05 adalah sebesar 0.109.
- Selanjutnya, dengan batasan yang sama seperti di atas, namun ukuran
sampelnya yang berbeda, yaitu 6, 10, 16 dan 40, laju kesalahan Tipe I
dapat mencapai 0,275.
Ragam yang lebih besar dengan ukuran
sampel yang lebih kecil akan mengakibatkan peningkatan tingkat kesalahan
Tipe I sehingga uji F cenderung liberal dimana nilai taraf nyata yang
kita tentukan 0.05, pada kenyataannya nilai α tersebut lebih longgar,
misalnya 0.10. Sebaliknya, Ragam yang lebih besar dengan ukuran sampel
yang lebih besar mengakibatkan berkurangnya power, sehingga uji F
cenderung lebih konservatif dimana nilai taraf nyata yang kita tentukan
0.05, pada kenyataannya nilai α tersebut lebih ketat, misalnya 0.01
(Coombs et al. 1996, Stevens, 2002).
2.4. Uji kehomogenan ragam
Terdapat beberapa alternatif untuk menguji apakah data percobaan sudah memenuhi asumsi kehomogenen ragam atau tidak.
-
Metode Grafis:
-
Uji Formal:
-
Terdapat beberapa tes formal untuk menguji kehomogenan ragam, misalnya uji Bartlett's, Hartley's, Cochran, Levene's.
Harus diperhatikan bahwa di antara uji
Formal tersebut ada yang sangat sensitif terhadap ketidak normalan data,
terutama terhadap data yang sebarannya cenderung menjulur ke arah kanan
(Positif skewness). Kedua, dan ini lebih penting, jika ukuran sampel
kecil, uji tes formal terkadang gagal dalam menolak H0,
sehingga kita akan menganggap bahwa ragam sudah homogen. Dengan kata
lain, apabila data tidak menyebar normal, maka uji kehomogenan ragam
tersebut tidak bisa diandalkan.
Akhirnya, uji homogenitas ragam hanya
memberikan sedikit informasi tentang penyebab yang mendasari
ketidakhomogenan ragam, dan teknik diagnostik (misalnya plot residual)
masih tetap dibutuhkan untuk memutuskan tindakan perbaikan yang sesuai.
2.5. Solusi
-
Menggunakan nilai taraf nyata yang
lebih ketat, misalnya 0.025 (sehingga kesalahan jenis I diharapkan akan
tetap berada di bawah 0.05)
-
Transformasi data
-
Menggunakan model pendugaan lain yang lebih sesuai
» Pengujian Kehomogenan Ragam data pengamatan akan dibahas pada topik tersendiri
3. Independensi (Kebebasan Galat / Independency)
Nilai residual dan data setiap pengamatan satuan percobaan harus saling bebas, baik di dalam perlakuan itu sendiri (within group) atau diantara perlakuan (between group). Apabila kondisi ini tidak terpenuhi, akan sulit untuk mendeteksi perbedaan nyata yang mungkin ada.
3.1. Penyebab Ketidakbebasan
3.2. Konsekuensi ketidakbebasan galat
Seringkali uji independensi ini di
abaikan oleh para peneliti, terutama peneliti dalam ilmu-ilmu sosial dan
perilaku. Hays (1981) dan Stevens (2002) menyatakan bahwa pelanggaran
terhadap independensi data merupakan masalah yang sangat serius dalam
analisis ragam. Konsekuensinya akan menyebabkan inflasi terhadap nilai
taraf nyata (α) yang sudah ditentukan. Sebagai contoh, Stevens (2002)
menyatakan bahwa meskipun indikasi adanya independensi di antara nilai
pengamatan hanya sedikit, namun akan meningkatkan nilai kesalahan tipe I
(nilai α - pengaruh perlakuan yang terdeteksi tidak benar) beberapa
kali lebih besar, misalnya apabila taraf nyata yang kita tentukan
sebesar 0.05, nilai taraf nyata aktual akan jauh lebih besar (misalnya,
0.10 atau 0.20).
3.3. Pengujian Ketidakbebasan Galat
3.4. Solusi
-
Asumsi kebebasan galat ini biasanya
bisa terpenuhi apabila pengacakan satuan percobaan sudah dilakukan
dengan benar (sesuai dengan prinsip-prinsip perancangan percobaan). Jadi
apabila susunan satuan percobaan anda tersusun secara sistematis, maka kemungkinan asumsi kebebasan galat akan dilanggar.
-
Transformasi data yang sesuai akan membantu dalam menghilangkan pengaruh dependensi ini.
» Pengujian independensi data pengamatan akan dibahas pada topik tersendiri
4. Pengaruh Aditif
Pengaruh dari faktor perlakuan dan
lingkungan bersifat aditif, maksudnya tinggi rendahnya respons
semata-mata akibat dari pengaruh penambahan perlakuan dan atau kelompok.
Pada model linier di atas, perlakuan (τi) dan galat (εij)
bersifat aditif, dengan kata lain pengaruh penambahan yang berasal dari
perlakuan bersifat konstan untuk setiap ulangan dan pengaruh ulangan
bersifat konstan untuk setiap perlakuan. Nilai Respons (Yij) merupakan nilai rata-rata umum ditambah dengan penambahan dari perlakuan dan galat.
Agar lebih mudah memahami, perhatikan
ilustrasi berikut: Misalkan nilai rata-rata umum (μ) = 8 dan pengaruh
penambahan dari masing-masing perlakuan (τi) serta pengaruh penambahan dari masing-masing ulangan/kelompok (βj) seperti terlihat pada tabel berikut. Untuk mempermudah pemisalan, anggap nilai εij = 0, sehingga nilai respons Yij = μ+ τi + βj + εij bisa dihitung.
|
Faktor A
|
Faktor B (Ulangan/Kelompok) |
Selisih Pengaruh ulangan |
| β1 = +1 |
β1= +2 |
| τ1 = +1 |
(8+1+1) = 10 |
(8+1+2) = 11 |
1 |
| τ2 = +3 |
(8+3+1) = 12 |
(8+3+2) = 13 |
1 |
| Selisih Pengaruh Perlakuan |
2 |
2 |
|
Pada tabel di atas anda perhatikan
terlihat bahwa pengaruh perlakuan konstan pada setiap ulangan dan
pengaruh ulangan (atau pengaruh kelompok bila anda menggunakan kelompok)
selalu konstan pada semua perlakuan. Bila ini yang terjadi, maka data
tersebut adalah bersifat aditif. Namun, apabila pengaruh tersebut tidak
bersifat aditif, melainkan multiplikatif, maka data reponsnya akan
tampak seperti pada tabel berikut.
| Faktor A |
Ulangan |
| β1 = +1 |
β1= +2 |
Selisih ulangan |
| τ1 = +1 |
(8x1x1) = 9 |
(8x1x2) = 10 |
1 |
| τ2 = +3 |
(8x3x1) = 11 |
(8x3x2) = 14 |
3 |
| Selisih Perlakuan |
2 |
4 |
|
Perhatikan, selisih baik dari pengaruh
penambahan perlakuan ataupun kelompok tidak lagi bersifat konstan!
Apabila ada pengaruh penambahan dari faktor lain diluar percobaan kita,
maka pengaruh dari faktor yang kita cobakan sudah tidak bersifat aditif
lagi, melainkan multiplikatif.
Lebih jelasnya, perhatikan perbandingan antara pengaruh aditif dan multiplikatif untuk rancangan acak kelompok berikut ini.
Tabel Perbandingan antara pengaruh aditif dan multiplikatif
| |
Faktor A |
|
| Faktor B |
τ1= +1 |
τ2= +2 |
τ3= +3 |
|
| β1= +1 |
2 |
3 |
4 |
Pengaruh aditif |
| 1 |
2 |
3 |
Pengaruh multiplikatif |
| 0 |
0.30 |
0.48 |
Pengaruh multiplikatif (log) |
| β2= +5 |
6 |
7 |
8 |
Pengaruh aditif |
| 5 |
10 |
15 |
Pengaruh multiplikatif |
| 0.70 |
1.00 |
1.18 |
Pengaruh multiplikatif (log) |
4.1. Penyebab
Ada pengaruh dari faktor lain diluar faktor yang kita cobakan:
- Pengaruh dari efek sisa penelitian sebelumnya.
- Terdapat interaksi antara perlakuan dengan faktor lain yang tidak
dimasukkan dalam model, seperti jenis kelamin, jenis varietas, dan
sebagainya.
- Dalam Rancangan Acak Kelompok, biasanya terjadi interaksi antara perlakuan dengan kelompok
4.2. Hubungan dengan kehomogenan ragam
Biasanya apabila data bersifat aditif,
maka data tersebut mempunyai ragam yang homogen. Sebaliknya apabila data
bersifat tidak aditif, maka data tersebut mempunyai ragam yang
heterogen. Artinya data yang tidak memenuhi pengaruh aditif akan
memiliki keragaman galat yang besar. Untuk melihat ragam galat dari
percobaan, anda bisa perhatikan kuadrat tengah (KT) galat pada tabel
analisis ragam anda. Semakin besar KT galat anda, maka akan
mengindikasikan semakin besar keragaman pada percobaan anda.
Pengaruh perlakuan dan kelompok dikatakan
aditif apabila pengaruh perlakuan selalu tetap pada setiap ulangan atau
kelompok dan pengaruh ulangan atau kelompok selalu tetap untuk semua
perlakuan.
4.3 Uji Ketakaditifan:
Model linier RAK: Yij = μ+ τi + βj + εij. Nilai galat, εij
disumsikan bersifat independent, homogen, dan berdistribusi normal.
Model bersifat aditif apabila interaksi antara perlakuan dan kelompok (τi * βj)
tidak signifikan. Apabila terdapat interaksi, maka uji-F tidak lagi
efisien dan ada kemungkinan terjadinya penarikan kesimpulan yang salah
karena pengaruh dari kedua faktor tidak lagi bersifat aditif melainkan
multiplikatif.
Uji untuk menguji apakah model bersifat aditif atau tidak adalah dengan menggunakan metode Tukey.
SS (ketidakaditifan) = (∑∑ τi βj y ij ) 2 / ( ∑ τi 2 )( ∑ βj 2 )
» Pengujian independensi data pengamatan akan dibahas pada topik tersendiri
4.4. Solusi:
5. Kesimpulan
Dari keempat asumsi di atas, asumsi yang paling umum dilanggar adalah asumsi kehomogenan ragam.
Apabila asumsi kehomogenan ragam terpenuhi, biasanya asumsi kenormalan
juga terpenuhi, namun hal sebaliknya tidak selalu terjadi.
Reff:
Angela Dean and Daniel Voss. 1999. Design and Analysis of Experiments. Springer Verlag New York, Inc.
Gerry P. Quinn & Michael J. Keough. 2002. Experimental Design and Data Analysis for Biologists. Cambridge University Press
Glenn Gamst, Lawrence S. Meyers, and A.
J. Guarino. 2008. Analysis of Variance Designs A Conceptual and
Computational Approach with SPSS and SAS. Cambridge University Press
Shirley Dowdy, Stanley Weardon, Daniel Chilko. 2004. Statistics for Research (Third Edition). John Wiley & Sons, Inc





 Hasil
uji di atas menggunakan uji Levene. nilai Levene F hitung adalah
sebesar 1.424 dengan signifikansi 0.252. Karena nilai sig > 0.05 maka
dapat disimpulkan bahwa tidak ada perbedaan varian antar kelompok
sampel yang diteliti atau varian antar kelompok sampel adalah sama.
Hasil
uji di atas menggunakan uji Levene. nilai Levene F hitung adalah
sebesar 1.424 dengan signifikansi 0.252. Karena nilai sig > 0.05 maka
dapat disimpulkan bahwa tidak ada perbedaan varian antar kelompok
sampel yang diteliti atau varian antar kelompok sampel adalah sama.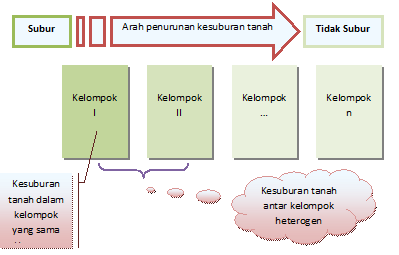
 . Dengan kata lain semakin kecil galat percobaan (
. Dengan kata lain semakin kecil galat percobaan (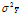 ) maka informasi yang diperoleh (I) akan semakin besar atau semakin besar ukuran satuan percobaan (n) maka galat percobaan semakin kecil dan informasi semakin besar.
) maka informasi yang diperoleh (I) akan semakin besar atau semakin besar ukuran satuan percobaan (n) maka galat percobaan semakin kecil dan informasi semakin besar.



















